一次由 DNS 解析服务失效引发的线上 DB 连接打满的事故经历
最近经历了一次由于线上 DNS 解析大范围失效引发的问题排查,并且由于应对不当导致的 MySQL 连接数打满。由于问题发上在周末,网络访问和内部沟通都不方便,整个问题的处理大概花费了 14 个小时(上午 10:00 左右到晚上 03:00)。
事故的起因是由于网络 DNS 解析失效,导致服务里面的一段发送 UDP 消息的代码超时,导致接口访问时长增加,导致后续请求在任务队列中排队并超时。排查发现问题之后紧急上线,导致所有服务节点重启之后连接 MySQL 出现域名解析问题,在处理请求的过程中不断创建连接,在域名解析恢复之后把 MySQL 的服务器的连接打满导致部分请求超时。连接打满之后再创建新连接就会失败,触发了一个连接池的 BUG,导致连接池会不断地创建连接,重启也不能解决问题。
🔗环境与背景
所涉及的服务记为 A 服务。
A 服务是一个线上服务,通过公司的私有云平台进行部署,一共 16 个服务实例。
A 服务背后使用的存储为 MySQL,缓存为 memcache。MySQL 使用主从配置,并使用了分库分表配置,一共 16 个子库:其中,0-7 库和 8-15 库分别部署于独立的 MySQL 实例上,并且分别设置了主从同步。
🔗数据库连接池
服务通过 tomcat dbcp 连接池控制数据库访问,A 服务所使用的数据库连接池版本为:
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-dhcp</artifactId>
<version>7.0.52</version>
</dependency>
A 服务的数据库访问模型如:
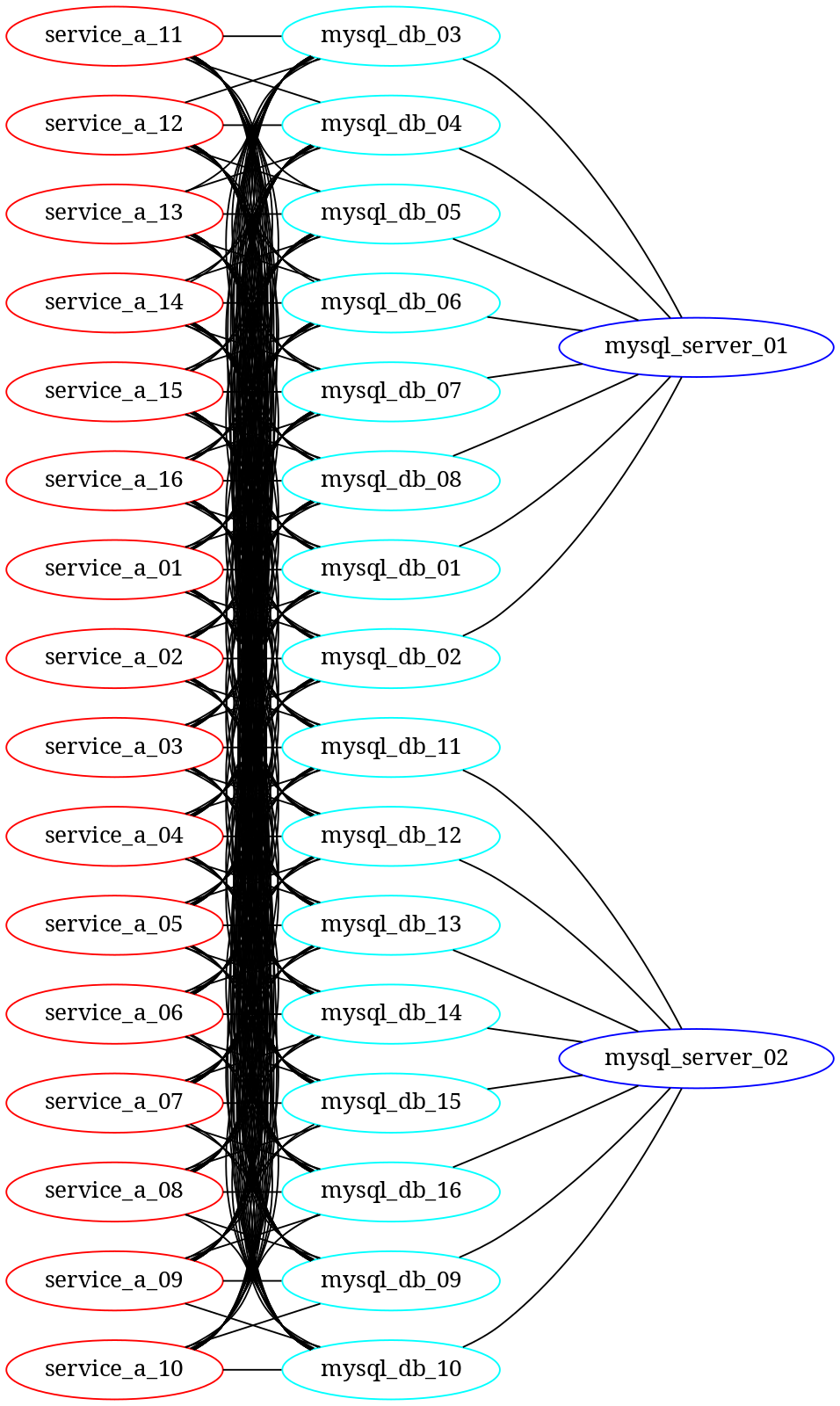
正常情况下,如果一个 A 服务实例和一个数据库的连接数为 m 的话,则:
- 对于 MySQL 数据库来说,会有来自 16*m 个 A 服务实例的连接
- 对于 MySQL 实例来说,会有 168m 个 A 服务实例的连接
- 对于 A 服务的实例来说,会有 16*m 个与数据库的连接
A 服务使用的连接池配置如下:
<initialSize>10</initialSize>
<maxActive>20</maxActive>
<maxWait>4000</maxWait>
<minIdle>10</minIdle>
<maxIdle>20</maxIdle>
🔗事故回顾
🔗开始出现服务抛弃量 10:30
从周末的上午 10:30 开始收到服务报警,提示服务的任务队列长时间堵塞导致任务队列中出现大量的任务由于等待超时被抛弃。
出现任务抛弃量,一般来说,说明服务遇到了多个处理耗时的任务请求。任务请求耗时较大,有可能是由于该操作实际耗时较长,如非分库字段的分库查询结果合并操作;也有可能是缓存访问超时。
出现了大量的任务抛弃量,当时的第一反应是,有业务线在批量调用耗时操作。所以通过 VPN 连接公司内网,查找有问题的调用方。发现调用方的情况正常,没有触发大量任务抛弃量的条件。
通过服务日志,发现服务运行基本正常:访问 cache 的监控正常,访问 MySQL 的监控正常。在服务器上检查网络、磁盘 IO等系统数据,没有发现异常。通过 GC 日志,发现 GC 正常。
当时线上环境的服务版本已经将近 1 个月没有变动,代码、配置和环境都没有改动。
在检查了当时能想到所有检查项之后,不能定位到问题所在。由于抛弃量的数量和频率还可以接受,所以着急没有重启服务,想要排查出来问题之后上线解决。
紧接着开始细粒度地排查监控项,从服务实例维度和服务方法维度检查服务抛弃量、异常量和请求耗时,发现 用户注册 和 用户登录 这两个服务方法的请求耗时明显较大。
对比方法逻辑,没有发现显著的问题点。
这时候,公司的技术支持群里面反馈说腾讯的 DNS 解析出现故障(其实该反馈出现较早,但是没有与 A 服务的抛弃量现象联系起来)。根据该信息排查代码,发现问题有可能是 UDP 消息发送超时。原来,该两个方法属于敏感接口,会在处理成功之后给指定服务地址发送一条操作的消息;该操作通过 UDP socket 操作,目标地址为内网域名,地址解析依赖于 腾讯的 DNS (公司的服务器托管给了腾讯云机房,包括A 服务所在的私有云集群服务器)。
经过分析之后,认为问题已经找到,可以通过修改目标地址的域名为 IP 地址解决问题。
结果开始了一个大悲剧。。。
🔗灰度上线 UDP IP 版本 14:30
在短暂评估之后,决定将修改了 UDP 目标地址的版本灰度上线。
灰度过程首先更新 1 个服务实例,在确认没有问题之后继续灰度 2 个实例。
在灰度过程中,监控一切正常,服务日志也没有异常(或者有少量异常,但是被忽略了,呵呵,当时主要还是太自信了)。已经灰度的服务实例上的监控数据确实显示任务请求耗时恢复到正常水平。
事后分析,其实腾讯 DNS 的解析故障发生后,公司的运维同事们就开始启用备用方案,将内网域名的解析的工作迁移到公司的备份服务器上。但是由于公司没有对方案进行过灾难演练,DNS 迁移又比较复杂,导致域名解析有时候正常有时候不正常。这样,在服务灰度数较少的时候,问题没有明显暴露出来。
在认为灰度没有问题之后,线上全量了服务的新版本。
🔗开始出现数据库连接数过高报警
第一个 MySQL 的连接数报警发生于 15:20。
每一个 MySQL 实例对于所能提供服务的连接数的限制是 5000。但是根据数据库连接池的配置来计算,到达每一个 MySQL 实例的最大连接数为 2560 (maxActive * 服务实例数 * 单实例数据库数)。
所以当时就反应过来,A 服务访问 cache 和 MySQL 都是通过域名来进行的。查看服务访问 cache 的监控,确实访问量有一个较大的下降。
当时已经发现了连接池不起作用,但是短时间内查不到连接池的 BUG 所在;所以决定临时修改 cache 和 mysql 访问的配置文件里面的目标地址配置,将域名修改为固定的 IP 地址。
🔗灰度上线缓存和 MySQL IP 版本 16:30
将 cache 和 MySQL 的访问域名修改为固定 IP 之后,上线。 MySQL 连接打满的问题没有得到缓解。
此时开始确定是 tomcat dbcp 连接池的问题,一方面与相关负责人沟通解决方案,一方面将有问题的服务实例摘除流量。
此时,A 服务的实例大部分对外响应正常,偶尔有 MySQL 请求超时。
与 DBA 沟通,发现有一个服务实例的连接数异常地多(4000+)。
- 重启之后,该实例的连接数下降,但是另外的几台实例的连接数迅速上升,出现一个最多的实例的连接数达到 2000+
- 再次重启之后,现象仍然存在
- 通过 DBA 手动 kill 连接,出现类似现象,连接数迅速上升直至打满
- 对 A 服务进行缩容,将实例个数从 16 降为 12,连接数过多现象不能得到缓解
发现重启服务和减少服务实例数不能解决问题,而且此时服务的访问量已经降到了一般以下(晚上10点以后),开始考虑从 MySQL 实例上想办法。
🔗上线只读 MySQL 从库版本
进一步发现,MySQL 只有主库出现连接打满的现象,从库正常工作。
此时,计划将所有的读请求转移到从库上,主库只处理写请求和少量的读请求。由于公司的私有云平台上线实在是太复杂,所以在物理服务器上部署新服务实例,只读 MySQL 从库。
MySQL 从库的连接数正常。
🔗下线读写主库版本
物理机上的服务实例启动后,现象仍然出现,可以判断问题与私有云平台无关(之前也怀疑过私有云平台有问题)。逐步把调用方的流量导流到物理机上,再逐步减少私有云的服务实例数,直到实例数为 1;在私有云实例减少的过程中,每减少一个实例,会导致其他实例的连接数增加,直到连接数再次打满。
私有云实例数降为 1 之后,此时已经是晚上 02:00,写请求每分钟 300+,果断迅速重启该实例。
该实例重启后,连接数得到控制。
🔗回复主库版本
连接数得到控制之后,逐步增加私有云服务的数量并导回流量,发现所有服务实例的连接数都得到控制,总的 MySQL 的连接数按预期逐步增加。直到所有的私有云实例得到恢复之后,连接数的变化都符合预期。
到此时,线上问题基本得到解决。
🔗连接池 BUG 分析
事后排查,发现连接池的 BUG DBCP-470 已经被发现并解决过了。
BUG 的分析参见 数据库连接泄漏问题 。简单地说,tomcat dbcp 连接池(BasicDataSource)在分配连接(getConnection)时,会先去创建一个内部的连接池(PoolingDataSource)实例;该实例依赖于:
- 先创建一个连接工厂(DriverConnectionFactory)对象和一个对象缓冲池(AbandonedObjectPool)对象
- 然后用该连接工厂对象和对象缓冲池对象去创建一个可缓冲的连接工厂(PoolableConnectionFactory)对象
- 成功之后再用该对象缓冲池对象创建连接池对象(PoolingDataSource)
问题在于,第 2 步不一定会成功。因为第 2 步虽然函数名为 createPoolableConnectionFactory,但实际上除了创建连接工厂对象之外,还会使用创建好的工厂对象建立一个数据库连接并测试连接的有效性(validateConnectionFactory),该过程是会抛出异常的。在 MySQL 服务端拒绝连接的情况下,该方法抛出的异常会导致第 3 步不会执行,从而导致每次调用 getConnection 时都会去创建一个对象缓冲池(AbandonedObjectPool)对象;该对象是一个池化对象的管理器,支持池化对象的提前创建和缓存逻辑,即当设置了 minIdle 次数时,该对象会创建并维持至少有 minIdle 个池化对象(当前为数据库连接对象)。这就使得只要有数据库请求超时(间接导致第 2 步失败),就可能造成数据库连接泄漏,直到数据库被打满。
🔗事故总结
- 类似于 UDP 消息这种优先级不是很高的操作,可以考虑放到单独的线程池异步执行,不能阻塞必要的请求处理逻辑。事实上,该 UDP 发送的消息虽然作为日志进行了收集,但是基本没有使用过,可以考虑删除掉;而且由于 UDP 是无连接的,每次发送消息都需要进行 DNS 解析,大大影响了服务的响应时间,放大了问题的严重级别,诱使了一系列的后续操作。
- 线上操作需要非常慎重。需要在沙箱环境验证后才能上线,直接在线上环境进行灰度有可能有安全隐患。
- 经验非常重要。在 DNS 失效的情况下,其实 cache 和 MySQL 的访问是不受影响的,因为连接是长期保活的;一旦重启服务,所有的连接的建立都是需要依赖于域名的解析的。DNS 出现问题需要意识到所有的通过域名访问的代码都会出问题。
- 常规的依赖(连接池等)需要跟进 BUG 情况。事后分析时,发现数据库连接池相关的 BUG 已经被修复,如果能及时跟进补丁情况,就能避免这次事故了。
- 线上服务依赖别的服务,需要做好容灾工作。服务调用的接口处需要详细的日志和错误处理;多个服务之间需要使用断路器(circuit breaker)做好隔离。